Random effects model
In statistics, a random effect(s) model, also called a variance components model is a kind of hierarchical linear model. It assumes that the dataset being analysed consists of a hierarchy of different populations whose differences relate to that hierarchy. In econometrics, random effects models are used in the analysis of hierarchical or panel data when one assumes no fixed effects (i.e. no individual effects). The fixed effects model is a special case of the random effects model. Note that this is not the case in biostatistics, where the econometric definition of the fixed effects model encompasses what biostatisticians call both the "fixed" and "random" effects.
Contents |
Simple example
Suppose m large elementary schools are chosen randomly from among thousands in a large country. Suppose also that n pupils of the same age are chosen randomly at each selected school. Their scores on a standard aptitude test are ascertained. Let Yij be the score of the jth pupil at the ith school. A simple way to model the relationships of these quantities is
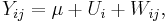
where μ is the average test score for the entire population. In this model Ui is the school-specific random effect: it measures the difference between the average score at school i and the average score in the entire country and it is "random" because the school has been randomly selected from a larger population of schools. The term, Wij is the individual-specific error. That is, it is the deviation of the j-th pupil’s score from the average for the i-th school. Again this is regarded as random because of the random selection of pupils within the school, even though it is a fixed quantity for any given pupil.
The model can be augmented by including additional explanatory variables, which would capture differences in scores among different groups. For example:
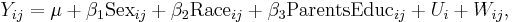
where Sexij is the dummy variable for boys/girls, Raceij is the dummy variable for white/black pupils, and ParentsEducij records the average education level of child’s parents. This is a mixed model, not a purely random effects model.
Variance components
The variance of Yij is the sum of the variances τ2 and σ2 of Ui and Wij respectively.
Let
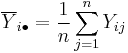
be the average, not of all scores at the ith school, but of those at the ith school that are included in the random sample. Let
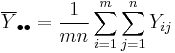
be the "grand average".
Let
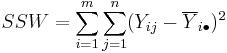
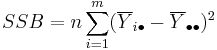
be respectively the sum of squares due to differences within groups and the sum of squares due to difference between groups. Then it can be shown that
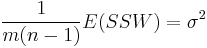
and
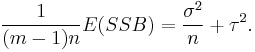
These "expected mean squares" can be used as the basis for estimation of the "variance components" σ2 and τ2.
Unbiasedness
In general, random effects is efficient, and should be used (over fixed effects) if the assumptions underlying it are believed to be satisfied. For RE to work in the school example it is necessary that the school-specific effects be orthogonal to the other covariates of the model. This can be tested by running random effects, then fixed effects, and doing a Hausman specification test. If the test rejects, then random effects is biased and fixed effects is the correct estimation procedure.
See also
References
- Fixed and random effects models
- Distinguishing Between Random and Fixed: Variables, Effects, and Coefficients
- How to Conduct a Meta-Analysis: Fixed and Random Effect Models
Bibliography
- Christensen, Ronald (2002). Plane Answers to Complex Questions: The Theory of Linear Models (Third ed.). New York: Springer. ISBN 0-387-95361-2.